

Volume 42 Number 3
Descriptive presentation of wound care data
John Stephenson
Keywords descriptive statistics, categorical, numerical, repeated measurements
For referencing Stephenson J. Descriptive presentation of wound care data. WCET® Journal 2022;42(3):30-33
DOI
https://doi.org/10.33235/wcet.42.3.30-33
Submitted 1 August 2022
Accepted 1 September 2022
Introduction
Most published quantitative research in the field of wound care will include elements of both descriptive and inferential statistics. Descriptive statistics, which normally precede the presentation of inferential tests, describe a study sample, using summary statistics, tables and graphs. No inference is involved. Inferential statistics, which includes significance testing and confidence intervals, is concerned with the inferences made from sample data to a wider parent population, and is not the subject of this editorial.
The aim of descriptive statistical analysis is to condense data in a meaningful way and extract useful information from it. Data may take various different forms, of which the distinction between two forms, categorical and numerical, is important for decision-making concerning the most appropriate method needed to provide an effective descriptive summary of the data. Categorical variables are sometimes further sub-divided into nominal variables (i.e. those where there is no underlying ordering to the categories) and ordinal variables (with some underlying order). The categories themselves are often termed levels.
In most wound care studies, the most common sources of data are probably the wound itself and the patient with the wound. An example of patient-level categorical data is patient sex (levels: male and female); an example of wound-level categorical data is tissue type (levels: slough, necrotic etc.) An example of patient-level numerical data is patient age in years; an example of wound-level numerical data is wound length. We may also collect and report data at the aggregate level; for example, the proportion of patients with a healed wound by 30 days, or the mean number of patients treated per month by a clinical team.
Sometimes the distinction between categorical and numerical data is not clear. Responses from questionnaire items, such as the commonly-encountered 5-point Likert questionnaire item, are, strictly speaking, ordinal, but are often treated as numerical, particularly when dealing with a score which is a sum of multiple items. Other types of data can be formulated as either categorical (e.g. the proportion of wounds healed within 30 days) or numerical (e.g. the number of days to healing), depending on the context and the aims of the study.
Presenting descriptive data in text and tables
Many wound care studies generate far too much data to present it all in text. Often only key results are presented in text, with the bulk of the data appearing in tabulated form, possibly in an appendix. Whether in text or in tabulated form, standard presentation for a numerical variable is a measure of average, followed by a measure of dispersion (i.e. spread) in brackets. The measure of average quoted is almost always the mean (i.e. arithmetic mean) or the median. Medians, which are not distorted by outlying values, are usually preferred when data is likely to be skewed – such as time to wound healing or some other event, or when we are dealing with ordinal quantities (such as the sum of Likert-style questionnaire items) which are assumed to be equivalent to numerical data – otherwise, the mean, which uses all the data values, is generally preferred.
The measure of dispersion quoted is usually either the standard deviation (commonly abbreviated to SD) or the range and/or inter-quartile range (commonly abbreviated to IQR). The range of a data set is easy to calculate (simply the difference between the two extreme values) but is based only on those two measures, disregarding all others. It is distorted by outliers. The IQR, which is calculated as the range from the 25th to the 75th percentile of the data, is more robust to distortion, but still does not take into account much of the data set.
By contrast, the SD uses every observation, but can be sensitive to outliers and is generally inappropriate for skewed data. It also has the advantage that it is always in the same units of measurement as the raw data, which can help with interpretation; in normally distributed data, approximately two thirds of all observations will lie within one standard deviation of the mean. So, for example, if we are told that the mean wound diameter in a large study of venous leg ulcers is 20mm, with an SD of 4mm, then if the data is normally distributed, we can infer that about two-thirds of wounds have a diameter between 16mm (1 SD below the mean) and 24mm (1 SD above the mean). The remaining one-third of wounds would be expected to be relative outliers, either below 16mm or above 24mm in diameter.
Common pairings for presenting descriptive data are mean and SD, median and range, and median and IQR. Other measures of average and spread, such as the geometric mean, mode and mid-range, are much less commonly encountered.
Standard presentation for a categorical variable is frequency, plus percentage and/or proportion. Generally valid percentages are quoted, disregarding invalid or missing data. For example, an audit of pressure injuries in a particular hospital ward ICU might record a number of Stage 1, 2 and 3 pressure injuries in ICU patients, but some patients on the ward are missed out from the audit. It would probably be more appropriate to quote the numbers of patients with a Stage 1 pressure injury as a proportion (and/or percentage) of the patients who were actually audited, not as a proportion of all patients.
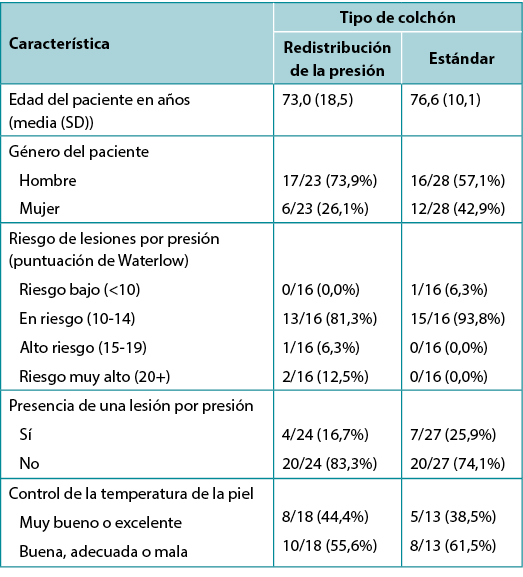
Table 1, adapted from Ousey et al.1, shows an example of tabulated data in a quite typical format. It includes both a numerical variable (age), summarised using mean and SD in each study group, and several categorical variables, summarised using frequency and valid percentage. Here the proportion is also given. The levels of each categorical variable considered are indented below the name of the variable itself. This amount of data would be difficult to absorb in text, and the side-by-side format of the table facilitates an easy comparison of group characteristics that would not be so apparent in data presented in text.
Table 1. Example of tabulated data [adapted1]
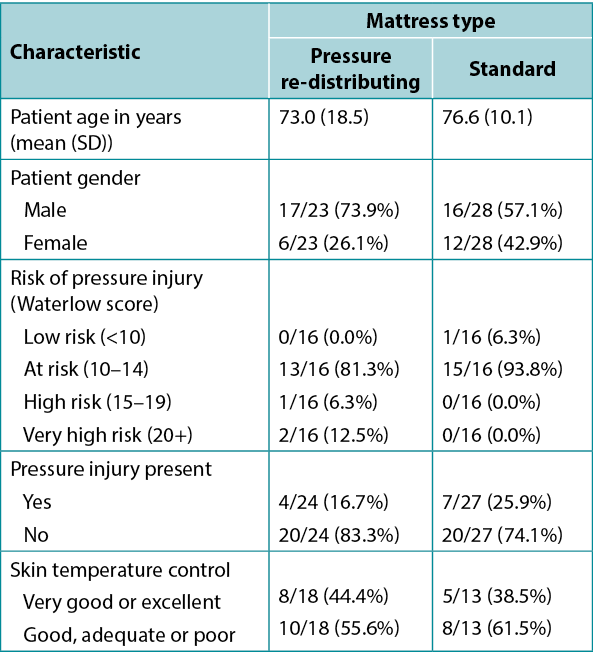
Note that the denominator is different for the different patient characteristics featured in the table; not all characteristics will have been reported on all patients. The levels of the Skin temperature control variable have been ‘condensed’ from five individual categories into two contrasting levels; this is a common device when data is spread too thinly across multiple levels for meaningful analysis, or when highlighting a contrast between two meaningful clinical states. The Waterlow variable has been transformed from its original numerical scale into an ordinal categorical variable; at the cost of a certain loss of information, this also allows comparison across levels of risk in common clinical use.
Presenting descriptive data in graphical form
Many different types of graphs are available, and most can be produced easily using modern software. Not all graphs are suitable for all types of data, however. Pie charts and bar charts are both designed to visually illustrate the relative frequencies of multiple levels of categorical variables. Despite its ubiquity, the pie chart does not seem to offer anything that a bar does not; most people find it harder to assess the relative size of sectors of a circle than they do of the heights of columns. Neither representation works well to display very large numbers of categories (which are hard to compare visually).
The bar chart can also be used to represent a quantity expressed as a proportion – Ousey et al.2 presented the proportion of patients with pressure ulceration pre- and post-implementation of a pressure reduction implementation programme in terms of a simple bar chart (Figure 1). The ‘whiskers’ around the bars represent confidence intervals, a measure of uncertainty in the quantity being measured.
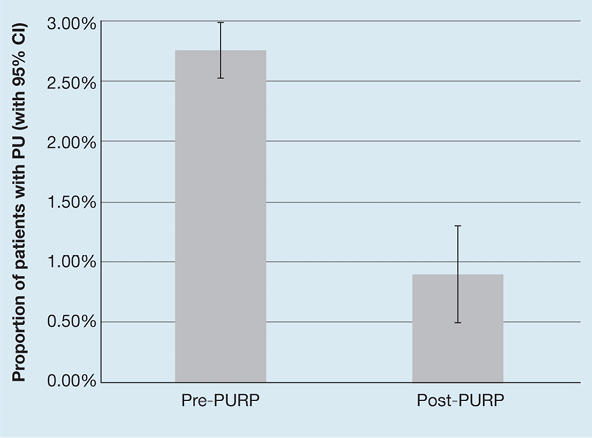
Figure 1. Example of a simple bar chart [adapted2]
A useful extension to the bar chart is the clustered bar chart which allows display of two factors concurrently. Figure 2 is a neat representation of the interplay between two categorical factors – pressure grading system status (with levels represented by the left- and right-hand clusters) and policy of referral (bars within a cluster).
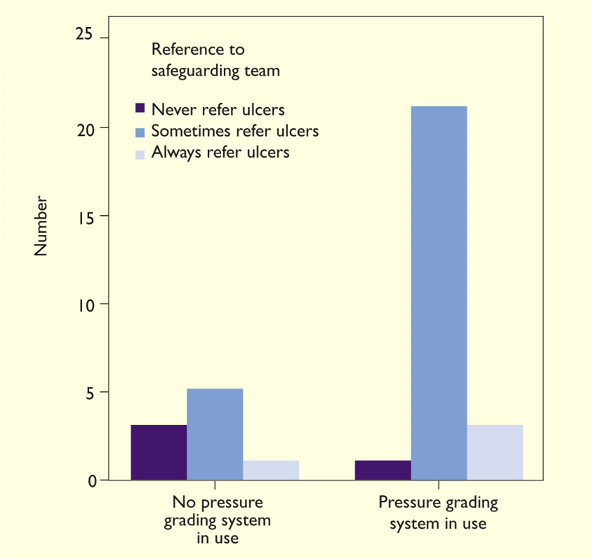
Figure 2. Example of a clustered bar chart [adapted3]
Different representations are required for numerical data. For example, a histogram, which is often confused with a bar chart, was used by Barakat-Johnson et al.4 to represent the time of response to communication with a wound specialist reported by patients using a digital app (Figure 3). It can be distinguished from a bar chart by the lack of gaps between the bars, reflecting the representation of a continuous measure rather than distinct categories. This sort of data can also be represented using a box plot, although box plots do not provide information about the full distribution of a data set.
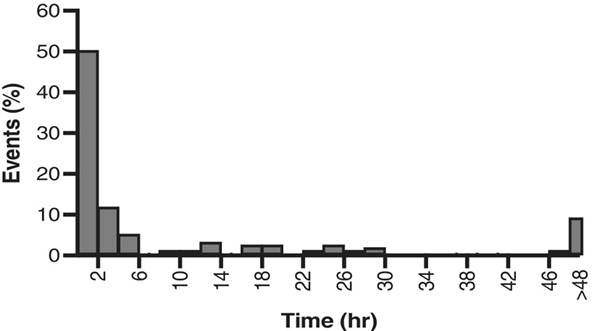
Figure 3. Example of a histogram [adapted4]
Mixed representation
The relationship between a numerical variable (such as peak pressure index) and categorical variables (such as BMI category and body position) can be neatly combined in a single representation using a line graph, as reported by Coyer et al.5. Figure 4 shows body position distinguished by the colour and shading of the line, and BMI category by the position on the x-axis.
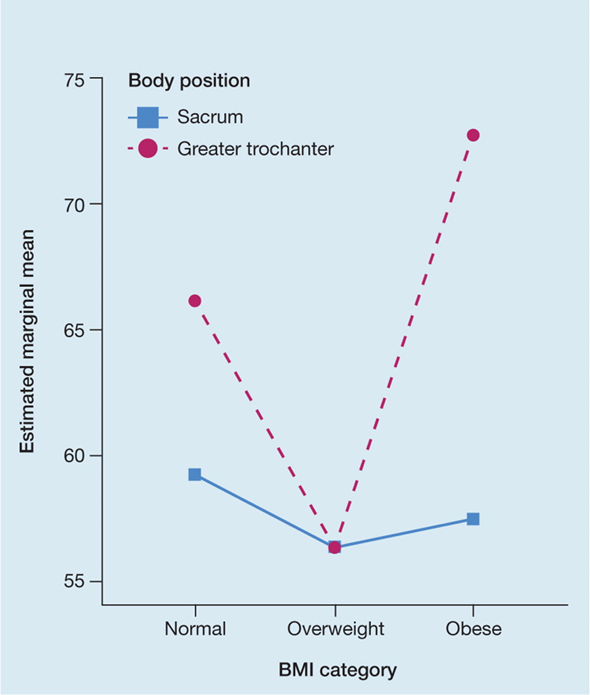
Figure 4. Example of a line graph [adapted5]
The key take-home message from this graph is that the factors interact – the effect on peak pressure of BMI category depends on where it is measured. This effect would not be immediately apparent had the same data been presented in tabulated form.
Repeated measures
Many wound care studies lend themselves to repeated measurements, for example, to examine the healing trajectory of a wound by monitoring its length at weekly intervals until healing, or investigating trends by audits of institutional aggregated data. Stephenson et al.6 presented longitudinal data (here, the number of observations of category 2 pressure injuries reported in a health organisation at monthly intervals over a period of several years) as a line graph (Figure 5), with the dotted line illustrating the underlying smoothed time-dependent trend. Here the graph is illustrating seasonal trends, an overall year-on-year downward trend, and the relationship between one data point and the preceding point (auto correlation) – effects that would be almost impossible to discern from tabulated data alone.
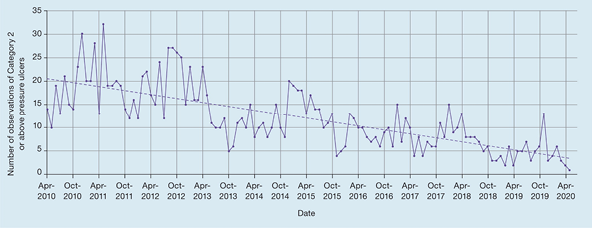
Figure 5. Example of a line graph showing longitudinal data [adapted6]
Tables or graphs?
It is not always easy to decide whether a table, graph or both is needed to summarise data. Graphs show trends and patterns in data, and the relationship between one variable and another, that would not necessarily be apparent in the same data presented in tabulated form. Tables give values to a level of precision that is generally unavailable in most graphical presentations.
Conclusions
Effective presentation of descriptive wound care data can allow a reader to quickly absorb trends and patterns in data, to compare group characteristics, and to assess the magnitude of effects. The questions that arise from wound care studies – in which we may be looking to compare the benefit of one treatment against another, maybe examine the change in wound parameters over time, or simply summarise the extent of wounds in an audit study – can often be answered simply and effectively using descriptive analysis, although, usually, such an analysis would be followed up with an inferential assessment. However, the ease with which modern software can generate graphs of any kind can sometimes be a barrier to effective communication. Many published examples exist of graphs that add little or nothing to understanding and need to be used with care.
While descriptive statistics do not facilitate drawing conclusions beyond available data or reject any study hypotheses, they can be a valuable way of adding insight to a study and require little or no specialist statistical knowledge to understand.
Presentación descriptiva de los datos sobre el cuidado de heridas
John Stephenson
DOI: https://doi.org/10.33235/wcet.42.3.30-33
Introducción
La mayoría de las investigaciones cuantitativas publicadas en el ámbito del cuidado de heridas incluyen elementos de estadística descriptiva e inferencial. Las estadísticas descriptivas, que normalmente preceden a la presentación de las pruebas inferenciales, describen una muestra de estudio, utilizando estadísticas de resumen, tablas y gráficos. No se trata de una inferencia. La estadística inferencial, que incluye las pruebas de significación y los intervalos de confianza, se ocupa de las inferencias realizadas a partir de los datos de la muestra a una población madre más amplia, y no es el objeto de este editorial.
El objetivo del análisis estadístico descriptivo es condensar los datos de forma significativa y extraer de ellos información útil. Los datos pueden adoptar varias formas diferentes, de las cuales la distinción entre dos formas, la categórica y la numérica, es importante para la toma de decisiones relativas al método más apropiado necesario para proporcionar un resumen descriptivo eficaz de los datos. Las variables categóricas se subdividen a veces en variables nominales (es decir, aquellas en las que no hay un orden subyacente a las categorías) y variables ordinales (con algún orden subyacente). Las propias categorías suelen denominarse niveles.
En la mayoría de los estudios sobre el cuidado de heridas, las fuentes de datos más comunes son probablemente la propia herida y el paciente con la herida. Un ejemplo de datos categóricos a nivel de paciente es el sexo del paciente (niveles: hombre y mujer); un ejemplo de datos categóricos a nivel de herida es el tipo de tejido (niveles: esfacelado, necrótico, etc.) Un ejemplo de datos numéricos a nivel de paciente es la edad del paciente en años; un ejemplo de datos numéricos a nivel de herida es la longitud de la herida. También podemos recopilar y comunicar datos a nivel global; por ejemplo, la proporción de pacientes con una herida curada a los 30 días, o el número medio de pacientes tratados al mes por un equipo clínico.
A veces, la distinción entre datos categóricos y numéricos no está clara. Las respuestas de los ítems del cuestionario, como el comúnmente encontrado ítem de Likert de 5 puntos, son, estrictamente hablando, ordinales, pero a menudo se tratan como numéricas, particularmente cuando se trata de una puntuación que es una suma de múltiples ítems. Otros tipos de datos pueden formularse como categóricos (por ejemplo, la proporción de heridas curadas en 30 días) o numéricos (por ejemplo, el número de días hasta la curación), según el contexto y los objetivos del estudio.
Presentación de datos descriptivos en texto y tablas
Muchos estudios sobre el cuidado de heridas generan demasiados datos para presentarlos todos en un texto. A menudo sólo se presentan los resultados clave en el texto, y el grueso de los datos aparece en forma de tabla, posiblemente en un apéndice. Ya sea en texto o en forma de tabla, la presentación estándar de una variable numérica es una medida de la media, seguida de una medida de la dispersión (es decir, la dispersión) entre paréntesis. La medida de la media citada es casi siempre la media (es decir, la media aritmética) o la mediana. Las medianas, que no están distorsionadas por los valores periféricos, suelen ser preferibles cuando los datos pueden estar sesgados -como el tiempo de curación de una herida o algún otro acontecimiento- o cuando se trata de cantidades ordinales (como la suma de los ítems de un cuestionario tipo Likert) que se suponen equivalentes a los datos numéricos; de lo contrario, se suele preferir la media, que utiliza todos los valores de los datos.
La medida de dispersión citada suele ser la desviación estándar (comúnmente abreviada como SD) o el rango y/o el rango intercuartil (comúnmente abreviado como IQR). El rango de un conjunto de datos es fácil de calcular (simplemente la diferencia entre los dos valores extremos), pero se basa sólo en esas dos medidas, sin tener en cuenta todas las demás. Está distorsionado por los valores atípicos. El IQR, que se calcula como el rango entre el percentil 25 y el 75 de los datos, es más robusto a la distorsión, pero sigue sin tener en cuenta gran parte del conjunto de datos.
Por el contrario, la SD utiliza todas las observaciones, pero puede ser sensible a los valores atípicos y, por lo general, es inadecuada para los datos sesgados. También tiene la ventaja de que siempre está en las mismas unidades de medida que los datos brutos, lo que puede ayudar a la interpretación; en los datos con distribución normal, aproximadamente dos tercios de todas las observaciones se encuentran dentro de una desviación estándar de la media. Así, por ejemplo, si nos dicen que el diámetro medio de la herida en un gran estudio de úlceras venosas de la pierna es de 20 mm, con una SD de 4 mm, entonces, si los datos se distribuyen normalmente, podemos deducir que aproximadamente dos tercios de las heridas tienen un diámetro entre 16 mm (1 SD por debajo de la media) y 24 mm (1 SD por encima de la media). El tercio restante de las heridas serían relativamente atípicas, ya sea por debajo de 16 mm o por encima de 24 mm de diámetro.
Los emparejamientos más comunes para presentar datos descriptivos son la media y la SD, la mediana y el rango, y la mediana y la IQR. Otras medidas de la media y la dispersión, como la media geométrica, la moda y el rango medio, son mucho menos frecuentes.
La presentación estándar para una variable categórica es la frecuencia, más el porcentaje y/o la proporción. En general, se citan los porcentajes válidos, sin tener en cuenta los datos no válidos o ausentes. Por ejemplo, una auditoría de las lesiones por presión en la UCI de una sala hospitalaria concreta puede registrar un número de lesiones por presión de estadio 1, 2 y 3 en pacientes de la UCI, pero algunos pacientes de la sala quedan fuera de la auditoría. Probablemente sería más apropiado citar el número de pacientes con una lesión por presión de fase 1 como una proporción (y/o porcentaje) de los pacientes que fueron realmente auditados, no como una proporción de todos los pacientes.
La tabla 1, adaptada de Ousey et al.1, muestra un ejemplo de datos tabulados en un formato bastante típico. Incluye tanto una variable numérica (la edad), resumida mediante la media y la SD en cada grupo de estudio, como varias variables categóricas, resumidas mediante la frecuencia y el porcentaje válido. Aquí también se da la proporción. Los niveles de cada variable categórica considerada están indentados debajo del nombre de la propia variable. Esta cantidad de datos sería difícil de asimilar en un texto, y el formato de la tabla, uno al lado del otro, facilita la comparación de las características de los grupos, que no serían tan evidentes en los datos presentados en un texto.
Obsérvese que el denominador es diferente para las distintas características de los pacientes que aparecen en la tabla; no todas las características se habrán comunicado en todos los pacientes. Los niveles de la variable Control de la temperatura de la piel se han "condensado" a partir de cinco categorías individuales en dos niveles contrastados; se trata de un recurso habitual cuando los datos están demasiado repartidos entre varios niveles para que el análisis sea significativo, o cuando se destaca un contraste entre dos estados clínicos significativos. La variable Waterlow se ha transformado de su escala numérica original a una variable categórica ordinal; a costa de una cierta pérdida de información, esto también permite la comparación entre niveles de riesgo de uso clínico común.
Tabla 1. Ejemplo de datos tabulados [adaptado1]
Presentación de datos descriptivos en forma de gráfico
Existen muchos tipos de gráficos, y la mayoría pueden elaborarse fácilmente con programas informáticos modernos. Sin embargo, no todos los gráficos son adecuados para todos los tipos de datos. Tanto los gráficos circulares como los de barras están diseñados para ilustrar visualmente las frecuencias relativas de múltiples niveles de variables categóricas. A pesar de su ubicuidad, el gráfico circular no parece ofrecer nada que no ofrezca una barra; a la mayoría de la gente le resulta más difícil evaluar el tamaño relativo de los sectores de un círculo que el de las alturas de las columnas. Ninguna de las dos representaciones funciona bien para mostrar un número muy grande de categorías (que son difíciles de comparar visualmente).
El gráfico de barras también puede utilizarse para representar una cantidad expresada como proporción: Ousey et al.2 presentaron la proporción de pacientes con úlceras por presión antes y después de la aplicación de un programa de reducción de la presión en forma de un simple gráfico de barras (Figura 1). Los "bigotes" alrededor de las barras representan los intervalos de confianza, una medida de la incertidumbre en la cantidad que se mide.
Figura 1. Ejemplo de gráfico de barras simple [adaptado2]
Una extensión útil del gráfico de barras es el gráfico de barras agrupadas, que permite visualizar dos factores simultáneamente. La figura 2 es una representación clara de la interacción entre dos factores categóricos: el estado del sistema de clasificación de la presión (con niveles representados por los grupos de la izquierda y la derecha) y la política de remisión (barras dentro de un grupo).
Figura 2. Ejemplo de gráfico de barras agrupadas [adaptado3]
Para los datos numéricos son necesarias diferentes representaciones. Por ejemplo, Barakat-Johnson et al.4 utilizaron un histograma, que a menudo se confunde con un gráfico de barras, para representar el tiempo de respuesta a la comunicación con un especialista en heridas que informaron los pacientes que utilizaban una aplicación digital (Figura 3). Se distingue de un gráfico de barras por la ausencia de espacios entre las barras, lo que refleja la representación de una medida continua en lugar de categorías distintas. Este tipo de datos también puede representarse mediante un gráfico de cajas, aunque los gráficos de cajas no proporcionan información sobre la distribución completa de un conjunto de datos.
Figura 3. Ejemplo de histograma [adaptado4]
Representación mixta
La relación entre una variable numérica (como el índice de presión máxima) y las variables categóricas (como la categoría de IMC y la posición corporal) puede combinarse claramente en una única representación mediante un gráfico de líneas, como informan Coyer et al.5. La figura 4 muestra la posición del cuerpo distinguida por el color y el sombreado de la línea, y la categoría del IMC por la posición en el eje x.
El mensaje clave que se desprende de este gráfico es que los factores interactúan: el efecto de la categoría de IMC sobre la presión máxima depende del lugar donde se mida. Este efecto no sería inmediatamente evidente si los mismos datos se hubieran presentado en forma de tabla.
Figura 4. Ejemplo de gráfico lineal [adaptado5]
Medidas repetidas
Muchos estudios sobre el cuidado de heridas se prestan a la realización de mediciones repetidas, por ejemplo, para examinar la trayectoria de curación de una herida mediante el seguimiento de su longitud a intervalos semanales hasta la curación, o para investigar las tendencias mediante auditorías de datos agregados institucionales. Stephenson et al.6 presentaron los datos longitudinales (en este caso, el número de observaciones de lesiones por presión de categoría 2 notificadas en una organización sanitaria a intervalos mensuales durante un periodo de varios años) como un gráfico de líneas (figura 5), en el que la línea de puntos ilustra la tendencia subyacente suavizada en función del tiempo. En este caso, el gráfico ilustra las tendencias estacionales, una tendencia general a la baja interanual y la relación entre un punto de datos y el anterior (autocorrelación), efectos que serían casi imposibles de discernir a partir de los datos tabulados únicamente.
Figura 5. Ejemplo de gráfico lineal que muestra datos longitudinales [adaptado6]
¿Tablas o gráficos?
No siempre es fácil decidir si se necesita una tabla, un gráfico o ambos para resumir los datos. Los gráficos muestran tendencias y patrones en los datos, así como la relación entre una variable y otra, que no necesariamente serían evidentes en los mismos datos presentados en forma de tabla. Las tablas proporcionan valores con un nivel de precisión que, por lo general, no está disponible en la mayoría de las presentaciones gráficas.
Conclusiones
Una presentación eficaz de los datos descriptivos sobre el cuidado de las heridas puede permitir al lector asimilar rápidamente las tendencias y los patrones de los datos, comparar las características de los grupos y evaluar la magnitud de los efectos. Las preguntas que surgen de los estudios sobre el cuidado de heridas -en los que podemos estar buscando comparar el beneficio de un tratamiento frente a otro, tal vez examinar el cambio en los parámetros de las heridas a lo largo del tiempo, o simplemente resumir la extensión de las heridas en un estudio de auditoría- a menudo pueden responderse de forma sencilla y eficaz utilizando el análisis descriptivo, aunque, por lo general, dicho análisis iría seguido de una evaluación inferencial. Sin embargo, la facilidad con la que los programas informáticos modernos pueden generar gráficos de cualquier tipo puede ser a veces un obstáculo para una comunicación eficaz. Existen muchos ejemplos publicados de gráficos que aportan poco o nada a la comprensión y deben utilizarse con cuidado.
Aunque las estadísticas descriptivas no facilitan la extracción de conclusiones más allá de los datos disponibles ni rechazan ninguna hipótesis del estudio, pueden ser una forma valiosa de añadir información a un estudio y su comprensión requiere pocos o ningún conocimiento estadístico especializado.
Author(s)
John Stephenson
PHD FRSS(GradStat) CMath(MIMA)
Senior Lecturer in Biomedical Statistics
University of Huddersfield, United Kingdom
Email J.Stephenson@hud.ac.uk
References
- Ousey K, Stephenson J, Fleming L. Evaluating the Trezzo range of static foam surfaces: results of a comparative study. Wounds UK 2016;12(4):66–73. ISSN 1746-6814.
- Ousey K, Stephenson J, Blackburn J. Sub-epidermal moisture assessment as an adjunct to visual assessment in the reduction of pressure ulcer incidence. J Wound Care 2022;31(3).
- Ousey K, Kaye V, McCormick K, Stephenson J. Investigating staff knowledge of safeguarding and pressure ulcers in care homes. J Wound Care 2016;25(1).
- Barakat-Johnson et al. The viability and acceptability of a Virtual Wound Care Command Centre in Australia. Int Wound J 2022;1–17.
- Coyer F, Clark M, Slattery P, Thomas P, McNamara G, Edwards C, Ingleman J, Stephenson J, Ousey K. Exploring pressures, tissue reperfusion and body positioning: a pilot evaluation. J Wound Care 2017;26(10).
- Stephenson J, Ousey K, Blackburn J, Javid F. Using past performance to improve future clinical outcomes in pressure ulcer prevention. J Wound Care 2021;30(6).

