
Volume 42 Number 3
Descriptive presentation of wound care data
John Stephenson
Keywords descriptive statistics, categorical, numerical, repeated measurements
For referencing Stephenson J. Descriptive presentation of wound care data. WCET® Journal 2022;42(3):30-33
DOI
https://doi.org/10.33235/wcet.42.3.30-33
Submitted 1 August 2022
Accepted 1 September 2022
Introduction
Most published quantitative research in the field of wound care will include elements of both descriptive and inferential statistics. Descriptive statistics, which normally precede the presentation of inferential tests, describe a study sample, using summary statistics, tables and graphs. No inference is involved. Inferential statistics, which includes significance testing and confidence intervals, is concerned with the inferences made from sample data to a wider parent population, and is not the subject of this editorial.
The aim of descriptive statistical analysis is to condense data in a meaningful way and extract useful information from it. Data may take various different forms, of which the distinction between two forms, categorical and numerical, is important for decision-making concerning the most appropriate method needed to provide an effective descriptive summary of the data. Categorical variables are sometimes further sub-divided into nominal variables (i.e. those where there is no underlying ordering to the categories) and ordinal variables (with some underlying order). The categories themselves are often termed levels.
In most wound care studies, the most common sources of data are probably the wound itself and the patient with the wound. An example of patient-level categorical data is patient sex (levels: male and female); an example of wound-level categorical data is tissue type (levels: slough, necrotic etc.) An example of patient-level numerical data is patient age in years; an example of wound-level numerical data is wound length. We may also collect and report data at the aggregate level; for example, the proportion of patients with a healed wound by 30 days, or the mean number of patients treated per month by a clinical team.
Sometimes the distinction between categorical and numerical data is not clear. Responses from questionnaire items, such as the commonly-encountered 5-point Likert questionnaire item, are, strictly speaking, ordinal, but are often treated as numerical, particularly when dealing with a score which is a sum of multiple items. Other types of data can be formulated as either categorical (e.g. the proportion of wounds healed within 30 days) or numerical (e.g. the number of days to healing), depending on the context and the aims of the study.
Presenting descriptive data in text and tables
Many wound care studies generate far too much data to present it all in text. Often only key results are presented in text, with the bulk of the data appearing in tabulated form, possibly in an appendix. Whether in text or in tabulated form, standard presentation for a numerical variable is a measure of average, followed by a measure of dispersion (i.e. spread) in brackets. The measure of average quoted is almost always the mean (i.e. arithmetic mean) or the median. Medians, which are not distorted by outlying values, are usually preferred when data is likely to be skewed – such as time to wound healing or some other event, or when we are dealing with ordinal quantities (such as the sum of Likert-style questionnaire items) which are assumed to be equivalent to numerical data – otherwise, the mean, which uses all the data values, is generally preferred.
The measure of dispersion quoted is usually either the standard deviation (commonly abbreviated to SD) or the range and/or inter-quartile range (commonly abbreviated to IQR). The range of a data set is easy to calculate (simply the difference between the two extreme values) but is based only on those two measures, disregarding all others. It is distorted by outliers. The IQR, which is calculated as the range from the 25th to the 75th percentile of the data, is more robust to distortion, but still does not take into account much of the data set.
By contrast, the SD uses every observation, but can be sensitive to outliers and is generally inappropriate for skewed data. It also has the advantage that it is always in the same units of measurement as the raw data, which can help with interpretation; in normally distributed data, approximately two thirds of all observations will lie within one standard deviation of the mean. So, for example, if we are told that the mean wound diameter in a large study of venous leg ulcers is 20mm, with an SD of 4mm, then if the data is normally distributed, we can infer that about two-thirds of wounds have a diameter between 16mm (1 SD below the mean) and 24mm (1 SD above the mean). The remaining one-third of wounds would be expected to be relative outliers, either below 16mm or above 24mm in diameter.
Common pairings for presenting descriptive data are mean and SD, median and range, and median and IQR. Other measures of average and spread, such as the geometric mean, mode and mid-range, are much less commonly encountered.
Standard presentation for a categorical variable is frequency, plus percentage and/or proportion. Generally valid percentages are quoted, disregarding invalid or missing data. For example, an audit of pressure injuries in a particular hospital ward ICU might record a number of Stage 1, 2 and 3 pressure injuries in ICU patients, but some patients on the ward are missed out from the audit. It would probably be more appropriate to quote the numbers of patients with a Stage 1 pressure injury as a proportion (and/or percentage) of the patients who were actually audited, not as a proportion of all patients.
Table 1, adapted from Ousey et al.1, shows an example of tabulated data in a quite typical format. It includes both a numerical variable (age), summarised using mean and SD in each study group, and several categorical variables, summarised using frequency and valid percentage. Here the proportion is also given. The levels of each categorical variable considered are indented below the name of the variable itself. This amount of data would be difficult to absorb in text, and the side-by-side format of the table facilitates an easy comparison of group characteristics that would not be so apparent in data presented in text.
Table 1. Example of tabulated data [adapted1]
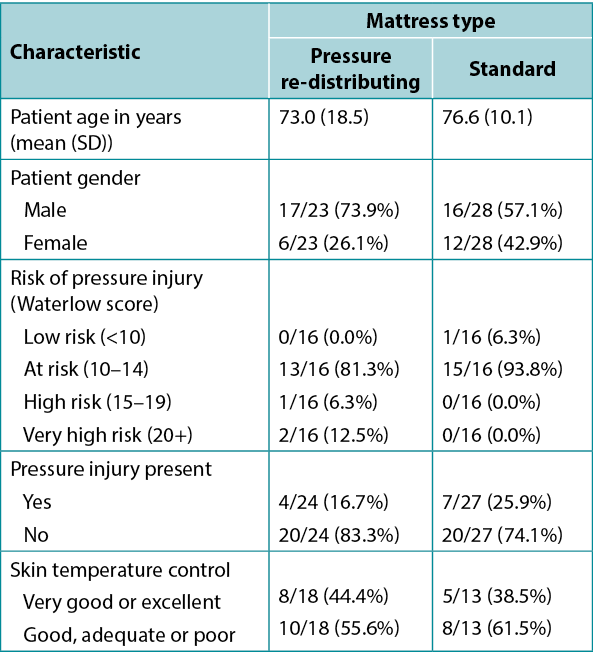
Note that the denominator is different for the different patient characteristics featured in the table; not all characteristics will have been reported on all patients. The levels of the Skin temperature control variable have been ‘condensed’ from five individual categories into two contrasting levels; this is a common device when data is spread too thinly across multiple levels for meaningful analysis, or when highlighting a contrast between two meaningful clinical states. The Waterlow variable has been transformed from its original numerical scale into an ordinal categorical variable; at the cost of a certain loss of information, this also allows comparison across levels of risk in common clinical use.
Presenting descriptive data in graphical form
Many different types of graphs are available, and most can be produced easily using modern software. Not all graphs are suitable for all types of data, however. Pie charts and bar charts are both designed to visually illustrate the relative frequencies of multiple levels of categorical variables. Despite its ubiquity, the pie chart does not seem to offer anything that a bar does not; most people find it harder to assess the relative size of sectors of a circle than they do of the heights of columns. Neither representation works well to display very large numbers of categories (which are hard to compare visually).
The bar chart can also be used to represent a quantity expressed as a proportion – Ousey et al.2 presented the proportion of patients with pressure ulceration pre- and post-implementation of a pressure reduction implementation programme in terms of a simple bar chart (Figure 1). The ‘whiskers’ around the bars represent confidence intervals, a measure of uncertainty in the quantity being measured.
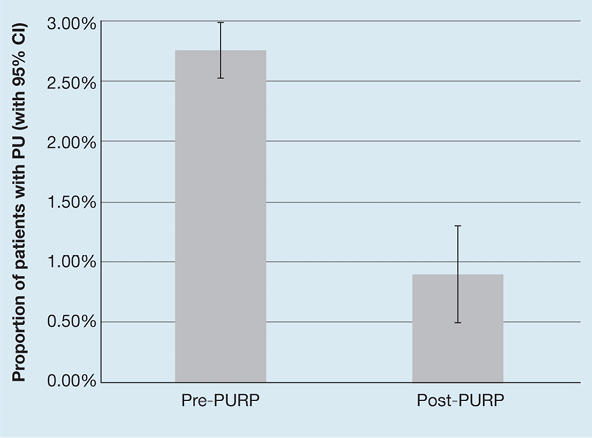
Figure 1. Example of a simple bar chart [adapted2]
A useful extension to the bar chart is the clustered bar chart which allows display of two factors concurrently. Figure 2 is a neat representation of the interplay between two categorical factors – pressure grading system status (with levels represented by the left- and right-hand clusters) and policy of referral (bars within a cluster).
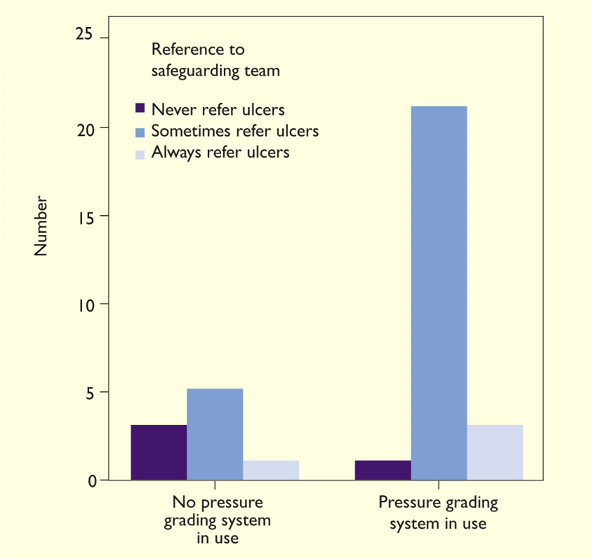
Figure 2. Example of a clustered bar chart [adapted3]
Different representations are required for numerical data. For example, a histogram, which is often confused with a bar chart, was used by Barakat-Johnson et al.4 to represent the time of response to communication with a wound specialist reported by patients using a digital app (Figure 3). It can be distinguished from a bar chart by the lack of gaps between the bars, reflecting the representation of a continuous measure rather than distinct categories. This sort of data can also be represented using a box plot, although box plots do not provide information about the full distribution of a data set.
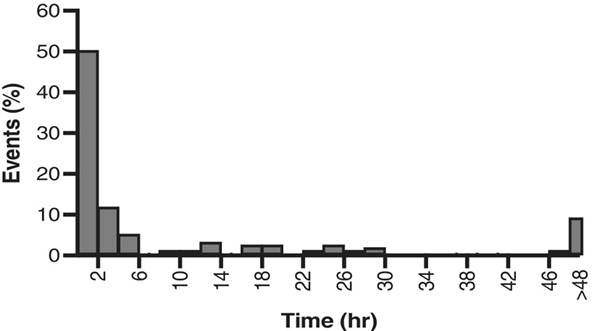
Figure 3. Example of a histogram [adapted4]
Mixed representation
The relationship between a numerical variable (such as peak pressure index) and categorical variables (such as BMI category and body position) can be neatly combined in a single representation using a line graph, as reported by Coyer et al.5. Figure 4 shows body position distinguished by the colour and shading of the line, and BMI category by the position on the x-axis.
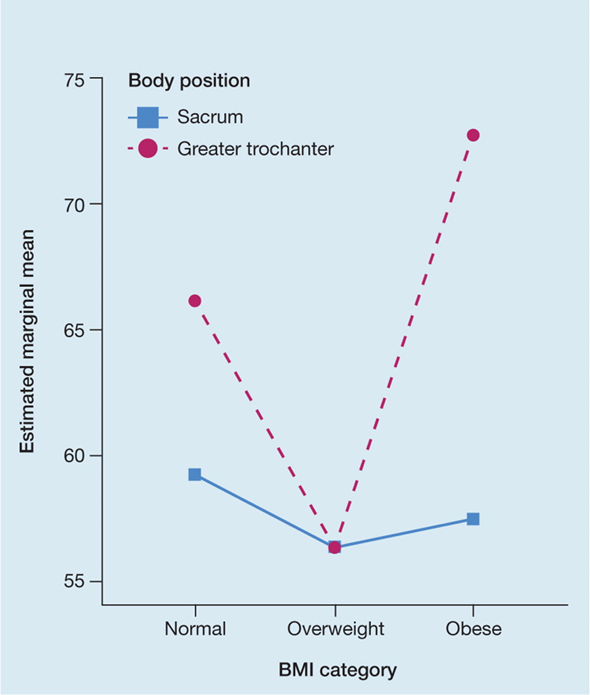
Figure 4. Example of a line graph [adapted5]
The key take-home message from this graph is that the factors interact – the effect on peak pressure of BMI category depends on where it is measured. This effect would not be immediately apparent had the same data been presented in tabulated form.
Repeated measures
Many wound care studies lend themselves to repeated measurements, for example, to examine the healing trajectory of a wound by monitoring its length at weekly intervals until healing, or investigating trends by audits of institutional aggregated data. Stephenson et al.6 presented longitudinal data (here, the number of observations of category 2 pressure injuries reported in a health organisation at monthly intervals over a period of several years) as a line graph (Figure 5), with the dotted line illustrating the underlying smoothed time-dependent trend. Here the graph is illustrating seasonal trends, an overall year-on-year downward trend, and the relationship between one data point and the preceding point (auto correlation) – effects that would be almost impossible to discern from tabulated data alone.
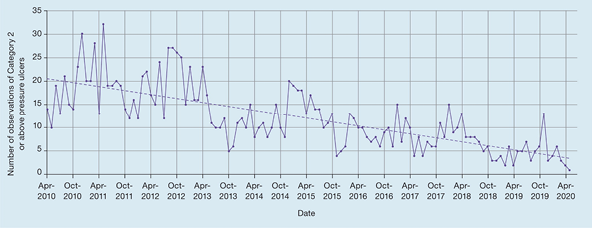
Figure 5. Example of a line graph showing longitudinal data [adapted6]
Tables or graphs?
It is not always easy to decide whether a table, graph or both is needed to summarise data. Graphs show trends and patterns in data, and the relationship between one variable and another, that would not necessarily be apparent in the same data presented in tabulated form. Tables give values to a level of precision that is generally unavailable in most graphical presentations.
Conclusions
Effective presentation of descriptive wound care data can allow a reader to quickly absorb trends and patterns in data, to compare group characteristics, and to assess the magnitude of effects. The questions that arise from wound care studies – in which we may be looking to compare the benefit of one treatment against another, maybe examine the change in wound parameters over time, or simply summarise the extent of wounds in an audit study – can often be answered simply and effectively using descriptive analysis, although, usually, such an analysis would be followed up with an inferential assessment. However, the ease with which modern software can generate graphs of any kind can sometimes be a barrier to effective communication. Many published examples exist of graphs that add little or nothing to understanding and need to be used with care.
While descriptive statistics do not facilitate drawing conclusions beyond available data or reject any study hypotheses, they can be a valuable way of adding insight to a study and require little or no specialist statistical knowledge to understand.
Présentation descriptive des données de traitement des plaies
John Stephenson
DOI: https://doi.org/10.33235/wcet.42.3.30-33
Introduction
La plupart des recherches quantitatives publiées dans le domaine du traitement des plaies comprennent des éléments de statistiques descriptives et inférentielles. Les statistiques descriptives, qui précèdent normalement la présentation des tests inférentiels, décrivent un échantillon d'étude, à l'aide de statistiques synthèses, de tableaux et de graphiques. Il ne s'agit pas de déduction. Les statistiques inférentielles, qui comprennent les tests de signification et les intervalles de confiance, concernent les déductions faites à partir d'un échantillon de données vers une population mère plus large, et ne font pas l'objet de cet article.
L'objectif de l'analyse statistique descriptive est de condenser les données de manière significative et d'en extraire des informations utiles. Les données peuvent prendre différentes formes, dont la distinction entre deux formes, catégorielle et numérique, est importante pour la prise de décision concernant la méthode la plus appropriée pour fournir une synthèse descriptive efficace des données. Les variables catégorielles sont parfois subdivisées en variables nominales (c'est-à-dire celles pour lesquelles il n'y a pas d'ordre sous-jacent aux catégories) et en variables ordinales (avec un certain ordre sous-jacent). Les catégories elles-mêmes sont souvent appelées niveaux.
Dans la plupart des études sur le traitement des plaies, les sources de données les plus courantes sont probablement la plaie elle-même et le patient souffrant de la plaie. Un exemple de données catégorielles au niveau-patient est le sexe du patient (niveaux : homme et femme); un exemple de données catégorielles au niveau-plaie est le type de tissu (niveaux : boue, nécrotique, etc.) Un exemple de données numériques au niveau-patient est l'âge du patient en années; un exemple de données numériques au niveau-plaie est la longueur de la plaie. Nous pouvons également collecter et communiquer des données au niveau cumulé; par exemple, la proportion de patients dont la plaie est cicatrisée dans les 30 jours, ou le nombre moyen de patients traités par mois par une équipe clinique.
Parfois, la distinction entre les données catégorielles et numériques n'est pas claire. Les réponses aux questions d'un questionnaire, comme le questionnaire Likert à 5 points, sont, à proprement parler, ordinales, mais sont souvent traitées comme numériques, en particulier lorsqu'il s'agit d'un score qui est la somme de plusieurs questions. D'autres types de données peuvent être formulées sous forme catégorielle (par exemple, la proportion de plaies cicatrisées dans les 30 jours) ou numérique (par exemple, le nombre de jours avant cicatrisation), selon le contexte et les objectifs de l'étude.
Présenter des données descriptives dans un texte et des tableaux
De nombreuses études sur le traitement des plaies génèrent beaucoup trop de données pour les présenter toutes dans un texte. Souvent, seuls les résultats clés sont présentés dans le texte, la majeure partie des données apparaissant sous forme de tableaux, éventuellement en annexe. Que ce soit dans un texte ou sous forme de tableau, la présentation standard d'une variable numérique est une mesure de la moyenne, suivie d'une mesure de la dispersion (c'est-à-dire de l'écart) entre parenthèses. La mesure de la moyenne citée est presque toujours la moyenne arithmétique ou la médiane. Les médianes, qui ne sont pas faussées par des valeurs aberrantes, sont généralement préférées lorsque les données sont susceptibles d'être faussées - comme le temps de cicatrisation d'une plaie ou un autre événement, ou lorsque nous traitons des quantités ordinales (comme la somme des éléments d'un questionnaire de type Likert) qui sont supposées être équivalentes à des données numériques - sinon, la moyenne, qui utilise toutes les valeurs des données, est généralement préférée.
La mesure de dispersion citée est généralement soit l'écart-type (communément abrégé en ET), soit l'étendue et/ou l'écart interquartile (communément abrégé en EIQ). L'étendue d'un ensemble de données est facile à calculer (il s'agit simplement de la différence entre les deux valeurs extrêmes) mais elle est basée uniquement sur ces deux mesures, sans tenir compte de toutes les autres. Elle est déformée par les valeurs aberrantes. L'EIQ, qui est calculé comme l'intervalle entre le 25e et le 75e percentile des données, est plus résistant aux distorsions, mais ne prend toujours pas en compte une grande partie de l'ensemble des données.
En revanche, l’ET utilise chaque observation, mais peut être sensible aux valeurs aberrantes et est généralement inapproprié pour les données asymétriques. Il présente également l'avantage d'être toujours exprimé dans les mêmes unités de mesure que les données brutes, ce qui peut faciliter l'interprétation. Dans le cas de données normalement distribuées, environ deux tiers de toutes les observations se situent à moins d'un écart type de la moyenne. Ainsi, par exemple, si l'on nous dit que le diamètre moyen de la plaie dans une grande étude sur les ulcères de jambe veineux est de 20 mm, avec un écart-type de 4 mm, alors si les données sont normalement distribuées, nous pouvons en déduire qu'environ deux tiers des plaies ont un diamètre compris entre 16 mm (1 écart-type en dessous de la moyenne) et 24 mm (1 écart-type au-dessus de la moyenne). Le tiers restant des plaies serait considéré comme des valeurs aberrantes, soit inférieures à 16 mm, soit supérieures à 24 mm de diamètre.
Les paires courantes pour présenter des données descriptives sont la moyenne et l’ET, la médiane et l'étendue, et la médiane et l'EIQ. D'autres mesures de la moyenne et de la dispersion, telles que la moyenne géométrique, le mode et le milieu, sont beaucoup moins courantes.
La présentation standard pour une variable catégorielle est la fréquence, plus le pourcentage et/ou la proportion. Des pourcentages généralement valides sont cités, sans tenir compte des données invalides ou manquantes. Par exemple, un audit des lésions de pression dans une unité de soins intensifs d'un hôpital particulier peut enregistrer un certain nombre de lésions de pression de stade 1, 2 et 3 chez des patients de l’USI, mais certains patients du service ne sont pas pris en compte dans l'audit. Il serait probablement plus approprié de citer le nombre de patients présentant une lésion de pression de stade 1 comme une proportion (et/ou un pourcentage) des patients qui ont été effectivement audités, et non comme une proportion de tous les patients.
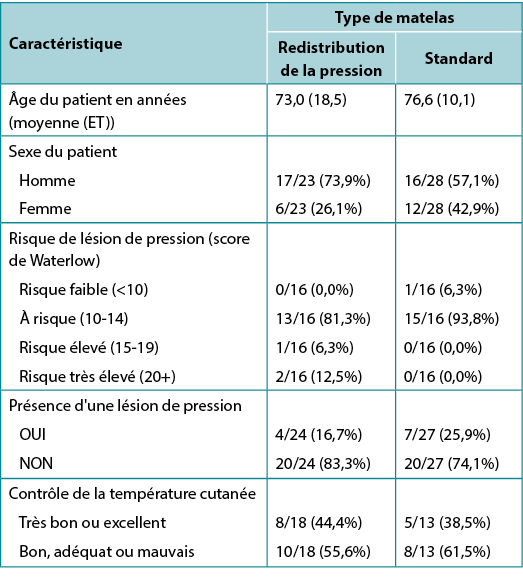
Le tableau 1, adapté de Ousey et al.1, montre un exemple de données sous forme de tableau dans un format assez typique. Il comprend à la fois une variable numérique (l'âge), synthétisée à l'aide de la moyenne et de l'écart-type dans chaque groupe d'étude, et plusieurs variables catégorielles, synthétisées à l'aide de la fréquence et du pourcentage valide. Ici, la proportion est également indiquée. Les niveaux de chaque variable catégorielle considérée sont indiqués sous le nom de la variable elle-même. Une telle quantité de données serait difficile à absorber dans un texte, et le format en colonnes justaposées du tableau facilite la comparaison des caractéristiques des groupes qui ne seraient pas aussi apparentes dans des données présentées dans un texte.
Notez que le dénominateur est différent pour les différentes caractéristiques des patients figurant dans le tableau; toutes les caractéristiques n'auront pas été compilées pour tous les patients. Les niveaux de la variable de contrôle de la température cutanée ont été "condensés" à partir de cinq catégories individuelles en deux niveaux contrastés. Il s'agit d'un dispositif courant lorsque les données sont trop dispersées sur plusieurs niveaux pour une analyse significative, ou lorsqu'il s'agit de mettre en évidence un contraste entre deux états cliniques significatifs. La variable de Waterlow a été transformée à partir de son échelle numérique originale en une variable catégorielle ordinale. Au prix d'une certaine perte d'information, cela permet également de comparer les niveaux de risque dans l'usage clinique courant.
Tableau 1. Exemple de données en tableau [adapté1]
Présenter des données descriptives sous forme de graphiques
Il existe de nombreux types de graphiques, et la plupart peuvent être produits facilement à l'aide des logiciels modernes. Cependant, tous les graphiques ne conviennent pas à tous les types de données. Les diagrammes en cercle (ou camemberts) et les diagrammes à barres (ou à bâtons) sont tous deux conçus pour illustrer visuellement les fréquences relatives de plusieurs niveaux de variables catégorielles. Malgré son omniprésence, le diagramme en cercle ne semble pas offrir quelque chose qu'une barre n'offre pas; la plupart des gens ont plus de mal à évaluer la taille relative des secteurs d'un cercle que la hauteur des colonnes. Aucune de ces deux représentations ne fonctionne bien pour afficher un très grand nombre de catégories (qui sont difficiles à comparer visuellement).
Le diagramme à barres peut également être utilisé pour représenter une quantité exprimée sous forme de proportion - Ousey et al.2 ont présenté la proportion de patients présentant des ulcères de pression avant et après la mise en œuvre d'un programme de réduction de la pression sous la forme d'un simple diagramme à barres (Figure 1). Les "moustaches" autour des barres représentent les intervalles de confiance, une mesure de l'incertitude de la quantité mesurée.
Figure 1. Exemple d'un diagramme à barres simple [adapté2]
Une extension utile du diagramme à barres est le diagramme à barres groupées qui permet d'afficher deux facteurs simultanément. La figure 2 est une représentation claire de l'interaction entre deux facteurs catégoriels - le statut du système de classement des pressions (les niveaux étant représentés par les groupes de gauche et de droite) et la politique d'orientation (barres à l'intérieur d’un groupe).
Figure 2. Exemple d'un diagramme à barres groupées [adapté3]
Différentes représentations sont nécessaires pour les données numériques. Par exemple, un histogramme, qui est souvent confondu avec un diagramme à barres, a été utilisé par Barakat-Johnson et al.4 pour représenter le temps de réponse à la communication avec un spécialiste des plaies rapporté par les patients utilisant une application numérique (Figure 3). Il se distingue d'un diagramme à barres par l'absence d'espaces entre les barres, ce qui reflète la représentation d'une mesure continue plutôt que de catégories distinctes. Ce type de données peut également être représenté à l'aide d'un diagramme en boîte (ou boîte à moustaches), bien que les diagrammes en boîte ne fournissent pas d'informations sur la distribution complète d'un ensemble de données.
Figure 3. Exemple d'un histogramme [adapté4]
Représentation mixte
La relation entre une variable numérique (telle que l'indice de pression maximale) et des variables catégorielles (telles que la catégorie d'IMC et la position du corps) peut être combinée de façon claire en une seule représentation à l'aide d'un graphique linéaire, comme le rapportent Coyer et al.5. La figure 4 montre la position du corps distinguée par la couleur et l'ombrage de la ligne, et la catégorie d'IMC par la position sur l'axe des abscisses.
Le principal message à retenir de ce graphique est que les facteurs interagissent - l'effet de la catégorie d'IMC sur la pression maximale dépend de l'endroit où elle est mesurée. Cet effet ne serait pas immédiatement apparent si les mêmes données avaient été présentées sous forme de tableau.
Figure 4. Exemple d'un graphique linéaire [adapté5]
Mesures répétées
De nombreuses études sur le traitement des plaies se prêtent à des mesures répétées, par exemple pour examiner la trajectoire de cicatrisation d'une plaie en surveillant son étendue à intervalles hebdomadaires jusqu'à la cicatrisation, ou pour étudier les tendances par des audits des données cumulées des institutions. Stephenson et al.6 ont présenté des données longitudinales (ici, le nombre d'observations de lésions de pression de catégorie 2 compilées dans un organisme de santé à des intervalles mensuels sur une période de plusieurs années) sous la forme d'un graphique linéaire (figure 5), la ligne en pointillés illustrant la tendance sous-jacente lissée en fonction du temps. Ici, le graphique illustre les tendances saisonnières, une tendance générale à la baisse d'une année sur l'autre et la relation entre un point de données et le point précédent (autocorrélation) - des effets qu'il serait presque impossible de discerner à partir de seules données sous forme de tableau.
Figure 5. Exemple d'un graphique linéaire montrant des données longitudinales [adapté6]
Tableaux ou graphiques ?
Il n'est pas toujours facile de décider si un tableau, un graphique ou les deux sont nécessaires pour synthétiser des données. Les graphiques montrent les tendances et les modèles des données, ainsi que la relation entre une variable et une autre, qui ne seraient pas nécessairement apparentes dans les mêmes données présentées sous forme de tableau. Les tableaux donnent des valeurs avec un niveau de précision qui n'est généralement pas disponible dans la plupart des présentations graphiques.
Conclusions
Une présentation efficace des données descriptives sur le traitement des plaies peut permettre au lecteur d'assimiler rapidement les tendances et les modèles des données, de comparer les caractéristiques des groupes et d'évaluer l'ampleur des effets. Les questions soulevées par les études sur le traitement des plaies - dans lesquelles nous cherchons à comparer les avantages d'un traitement par rapport à un autre, à examiner l'évolution des paramètres des plaies au fil du temps, ou simplement à résumer l'étendue des plaies dans le cadre d'une étude d'audit - peuvent souvent trouver une réponse simple et efficace grâce à l'analyse descriptive, bien que, généralement, une telle analyse soit suivie d'une évaluation inférentielle. Cependant, la facilité avec laquelle les logiciels modernes peuvent générer des graphiques de toutes sortes peut parfois constituer un obstacle à une communication efficace. Il existe de nombreux exemples publiés de graphiques qui n'apportent rien ou presque à la compréhension et qui doivent être utilisés avec précaution.
Bien que les statistiques descriptives ne permettent pas de tirer des conclusions au-delà des données disponibles ni de rejeter les hypothèses de l'étude, elles peuvent être un moyen précieux d'ajouter un éclairage à une étude et ne nécessitent que peu ou pas de connaissances statistiques spécialisées pour être comprises.
Author(s)
John Stephenson
PHD FRSS(GradStat) CMath(MIMA)
Senior Lecturer in Biomedical Statistics
University of Huddersfield, United Kingdom
Email J.Stephenson@hud.ac.uk
References
- Ousey K, Stephenson J, Fleming L. Evaluating the Trezzo range of static foam surfaces: results of a comparative study. Wounds UK 2016;12(4):66–73. ISSN 1746-6814.
- Ousey K, Stephenson J, Blackburn J. Sub-epidermal moisture assessment as an adjunct to visual assessment in the reduction of pressure ulcer incidence. J Wound Care 2022;31(3).
- Ousey K, Kaye V, McCormick K, Stephenson J. Investigating staff knowledge of safeguarding and pressure ulcers in care homes. J Wound Care 2016;25(1).
- Barakat-Johnson et al. The viability and acceptability of a Virtual Wound Care Command Centre in Australia. Int Wound J 2022;1–17.
- Coyer F, Clark M, Slattery P, Thomas P, McNamara G, Edwards C, Ingleman J, Stephenson J, Ousey K. Exploring pressures, tissue reperfusion and body positioning: a pilot evaluation. J Wound Care 2017;26(10).
- Stephenson J, Ousey K, Blackburn J, Javid F. Using past performance to improve future clinical outcomes in pressure ulcer prevention. J Wound Care 2021;30(6).