

Volume 42 Number 3
Descriptive presentation of wound care data
John Stephenson
Keywords descriptive statistics, categorical, numerical, repeated measurements
For referencing Stephenson J. Descriptive presentation of wound care data. WCET® Journal 2022;42(3):30-33
DOI
https://doi.org/10.33235/wcet.42.3.30-33
Submitted 1 August 2022
Accepted 1 September 2022
Introduction
Most published quantitative research in the field of wound care will include elements of both descriptive and inferential statistics. Descriptive statistics, which normally precede the presentation of inferential tests, describe a study sample, using summary statistics, tables and graphs. No inference is involved. Inferential statistics, which includes significance testing and confidence intervals, is concerned with the inferences made from sample data to a wider parent population, and is not the subject of this editorial.
The aim of descriptive statistical analysis is to condense data in a meaningful way and extract useful information from it. Data may take various different forms, of which the distinction between two forms, categorical and numerical, is important for decision-making concerning the most appropriate method needed to provide an effective descriptive summary of the data. Categorical variables are sometimes further sub-divided into nominal variables (i.e. those where there is no underlying ordering to the categories) and ordinal variables (with some underlying order). The categories themselves are often termed levels.
In most wound care studies, the most common sources of data are probably the wound itself and the patient with the wound. An example of patient-level categorical data is patient sex (levels: male and female); an example of wound-level categorical data is tissue type (levels: slough, necrotic etc.) An example of patient-level numerical data is patient age in years; an example of wound-level numerical data is wound length. We may also collect and report data at the aggregate level; for example, the proportion of patients with a healed wound by 30 days, or the mean number of patients treated per month by a clinical team.
Sometimes the distinction between categorical and numerical data is not clear. Responses from questionnaire items, such as the commonly-encountered 5-point Likert questionnaire item, are, strictly speaking, ordinal, but are often treated as numerical, particularly when dealing with a score which is a sum of multiple items. Other types of data can be formulated as either categorical (e.g. the proportion of wounds healed within 30 days) or numerical (e.g. the number of days to healing), depending on the context and the aims of the study.
Presenting descriptive data in text and tables
Many wound care studies generate far too much data to present it all in text. Often only key results are presented in text, with the bulk of the data appearing in tabulated form, possibly in an appendix. Whether in text or in tabulated form, standard presentation for a numerical variable is a measure of average, followed by a measure of dispersion (i.e. spread) in brackets. The measure of average quoted is almost always the mean (i.e. arithmetic mean) or the median. Medians, which are not distorted by outlying values, are usually preferred when data is likely to be skewed – such as time to wound healing or some other event, or when we are dealing with ordinal quantities (such as the sum of Likert-style questionnaire items) which are assumed to be equivalent to numerical data – otherwise, the mean, which uses all the data values, is generally preferred.
The measure of dispersion quoted is usually either the standard deviation (commonly abbreviated to SD) or the range and/or inter-quartile range (commonly abbreviated to IQR). The range of a data set is easy to calculate (simply the difference between the two extreme values) but is based only on those two measures, disregarding all others. It is distorted by outliers. The IQR, which is calculated as the range from the 25th to the 75th percentile of the data, is more robust to distortion, but still does not take into account much of the data set.
By contrast, the SD uses every observation, but can be sensitive to outliers and is generally inappropriate for skewed data. It also has the advantage that it is always in the same units of measurement as the raw data, which can help with interpretation; in normally distributed data, approximately two thirds of all observations will lie within one standard deviation of the mean. So, for example, if we are told that the mean wound diameter in a large study of venous leg ulcers is 20mm, with an SD of 4mm, then if the data is normally distributed, we can infer that about two-thirds of wounds have a diameter between 16mm (1 SD below the mean) and 24mm (1 SD above the mean). The remaining one-third of wounds would be expected to be relative outliers, either below 16mm or above 24mm in diameter.
Common pairings for presenting descriptive data are mean and SD, median and range, and median and IQR. Other measures of average and spread, such as the geometric mean, mode and mid-range, are much less commonly encountered.
Standard presentation for a categorical variable is frequency, plus percentage and/or proportion. Generally valid percentages are quoted, disregarding invalid or missing data. For example, an audit of pressure injuries in a particular hospital ward ICU might record a number of Stage 1, 2 and 3 pressure injuries in ICU patients, but some patients on the ward are missed out from the audit. It would probably be more appropriate to quote the numbers of patients with a Stage 1 pressure injury as a proportion (and/or percentage) of the patients who were actually audited, not as a proportion of all patients.
Table 1, adapted from Ousey et al.1, shows an example of tabulated data in a quite typical format. It includes both a numerical variable (age), summarised using mean and SD in each study group, and several categorical variables, summarised using frequency and valid percentage. Here the proportion is also given. The levels of each categorical variable considered are indented below the name of the variable itself. This amount of data would be difficult to absorb in text, and the side-by-side format of the table facilitates an easy comparison of group characteristics that would not be so apparent in data presented in text.
Table 1. Example of tabulated data [adapted1]
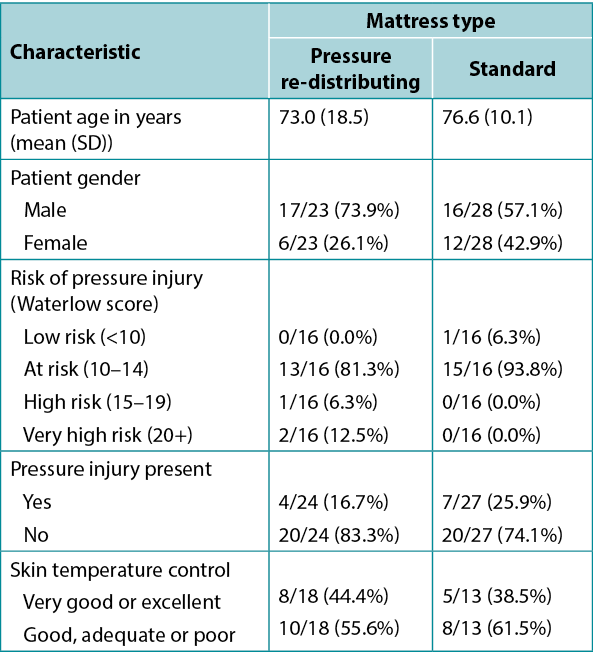
Note that the denominator is different for the different patient characteristics featured in the table; not all characteristics will have been reported on all patients. The levels of the Skin temperature control variable have been ‘condensed’ from five individual categories into two contrasting levels; this is a common device when data is spread too thinly across multiple levels for meaningful analysis, or when highlighting a contrast between two meaningful clinical states. The Waterlow variable has been transformed from its original numerical scale into an ordinal categorical variable; at the cost of a certain loss of information, this also allows comparison across levels of risk in common clinical use.
Presenting descriptive data in graphical form
Many different types of graphs are available, and most can be produced easily using modern software. Not all graphs are suitable for all types of data, however. Pie charts and bar charts are both designed to visually illustrate the relative frequencies of multiple levels of categorical variables. Despite its ubiquity, the pie chart does not seem to offer anything that a bar does not; most people find it harder to assess the relative size of sectors of a circle than they do of the heights of columns. Neither representation works well to display very large numbers of categories (which are hard to compare visually).
The bar chart can also be used to represent a quantity expressed as a proportion – Ousey et al.2 presented the proportion of patients with pressure ulceration pre- and post-implementation of a pressure reduction implementation programme in terms of a simple bar chart (Figure 1). The ‘whiskers’ around the bars represent confidence intervals, a measure of uncertainty in the quantity being measured.
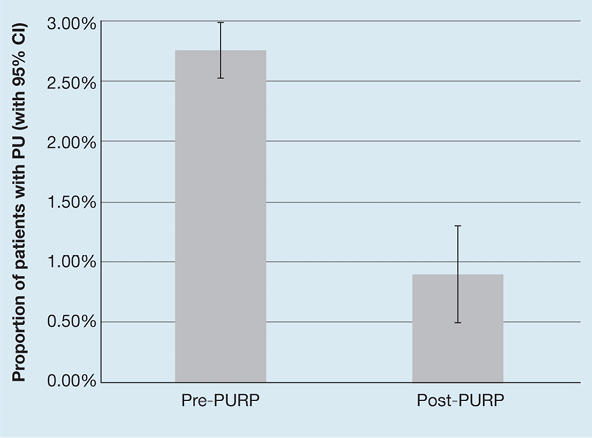
Figure 1. Example of a simple bar chart [adapted2]
A useful extension to the bar chart is the clustered bar chart which allows display of two factors concurrently. Figure 2 is a neat representation of the interplay between two categorical factors – pressure grading system status (with levels represented by the left- and right-hand clusters) and policy of referral (bars within a cluster).
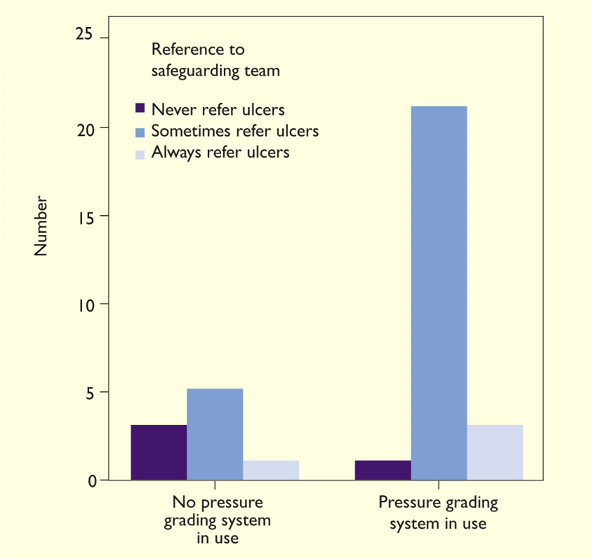
Figure 2. Example of a clustered bar chart [adapted3]
Different representations are required for numerical data. For example, a histogram, which is often confused with a bar chart, was used by Barakat-Johnson et al.4 to represent the time of response to communication with a wound specialist reported by patients using a digital app (Figure 3). It can be distinguished from a bar chart by the lack of gaps between the bars, reflecting the representation of a continuous measure rather than distinct categories. This sort of data can also be represented using a box plot, although box plots do not provide information about the full distribution of a data set.
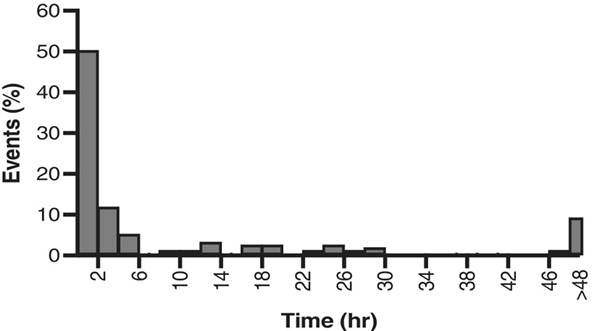
Figure 3. Example of a histogram [adapted4]
Mixed representation
The relationship between a numerical variable (such as peak pressure index) and categorical variables (such as BMI category and body position) can be neatly combined in a single representation using a line graph, as reported by Coyer et al.5. Figure 4 shows body position distinguished by the colour and shading of the line, and BMI category by the position on the x-axis.
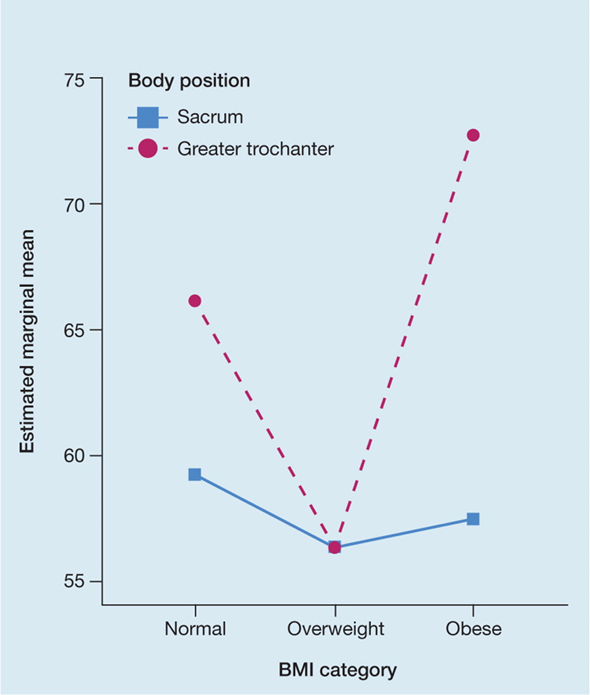
Figure 4. Example of a line graph [adapted5]
The key take-home message from this graph is that the factors interact – the effect on peak pressure of BMI category depends on where it is measured. This effect would not be immediately apparent had the same data been presented in tabulated form.
Repeated measures
Many wound care studies lend themselves to repeated measurements, for example, to examine the healing trajectory of a wound by monitoring its length at weekly intervals until healing, or investigating trends by audits of institutional aggregated data. Stephenson et al.6 presented longitudinal data (here, the number of observations of category 2 pressure injuries reported in a health organisation at monthly intervals over a period of several years) as a line graph (Figure 5), with the dotted line illustrating the underlying smoothed time-dependent trend. Here the graph is illustrating seasonal trends, an overall year-on-year downward trend, and the relationship between one data point and the preceding point (auto correlation) – effects that would be almost impossible to discern from tabulated data alone.
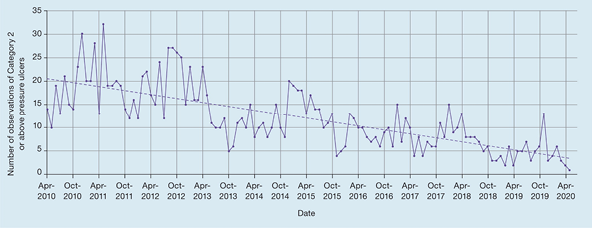
Figure 5. Example of a line graph showing longitudinal data [adapted6]
Tables or graphs?
It is not always easy to decide whether a table, graph or both is needed to summarise data. Graphs show trends and patterns in data, and the relationship between one variable and another, that would not necessarily be apparent in the same data presented in tabulated form. Tables give values to a level of precision that is generally unavailable in most graphical presentations.
Conclusions
Effective presentation of descriptive wound care data can allow a reader to quickly absorb trends and patterns in data, to compare group characteristics, and to assess the magnitude of effects. The questions that arise from wound care studies – in which we may be looking to compare the benefit of one treatment against another, maybe examine the change in wound parameters over time, or simply summarise the extent of wounds in an audit study – can often be answered simply and effectively using descriptive analysis, although, usually, such an analysis would be followed up with an inferential assessment. However, the ease with which modern software can generate graphs of any kind can sometimes be a barrier to effective communication. Many published examples exist of graphs that add little or nothing to understanding and need to be used with care.
While descriptive statistics do not facilitate drawing conclusions beyond available data or reject any study hypotheses, they can be a valuable way of adding insight to a study and require little or no specialist statistical knowledge to understand.
Apresentação descritiva dos dados relativos ao tratamento de feridas
John Stephenson
DOI: https://doi.org/10.33235/wcet.42.3.30-33
Introdução
A maioria da investigação quantitativa publicada no domínio dos cuidados com feridas incluirá elementos de estatística descritiva e inferencial. As estatísticas descritivas, que normalmente precedem a apresentação de testes inferenciais, descrevem uma amostra de estudo, utilizando estatísticas sumárias, tabelas e gráficos. Não está envolvida qualquer inferência. As estatísticas inferenciais, as quais incluem testes de significância e intervalos de confiança, estão relacionadas com as inferências feitas a partir de dados de amostra para uma população mãe mais vasta e não são o tema deste editorial.
O objetivo da análise estatística descritiva é o de condensar os dados de uma forma significativa e extrair dos mesmos informações úteis. Os dados podem assumir várias formas distintas, das quais a diferenciação entre duas formas, categórica e numérica, é importante para a tomada de decisões sobre o método mais apropriado necessário para fornecer um resumo descritivo eficaz dos dados. As variáveis categóricas são por vezes subdivididas em variáveis nominais (ou seja, aquelas em que não existe uma ordem subjacente às categorias) e em variáveis ordinais (com alguma ordem subjacente). As próprias categorias são frequentemente designadas por níveis.
Na maioria dos estudos de cuidados com feridas, as fontes de dados mais comuns são provavelmente a própria ferida e o paciente com a ferida. Um exemplo de dados categóricos ao nível do paciente é o sexo do paciente (níveis: masculino e feminino); um exemplo de dados categóricos ao nível da ferida é o tipo de tecido (níveis: viscosidade, necrótico, etc.) Um exemplo de dados numéricos ao nível do paciente é a idade do paciente em anos; um exemplo de dados numéricos ao nível da ferida é o comprimento da ferida. Também se podem recolher e comunicar dados a um nível agregado; por exemplo, a proporção de pacientes com uma ferida cicatrizada em 30 dias, ou o número médio de pacientes tratados por mês por uma equipa clínica.
Por vezes, a distinção entre dados categóricos e numéricos não é clara. As respostas aos itens do questionário, tais como o item do questionário Likert de 5 pontos que é normalmente encontrado, são, estritamente falando, ordinais, mas são frequentemente tratadas como sendo numéricas, particularmente quando se trata de uma pontuação que é uma soma de vários itens. Outros tipos de dados podem ser formulados como categóricos (por exemplo, a proporção de feridas saradas em 30 dias) ou como numéricos (por exemplo, o número de dias até à cicatrização), dependendo do contexto e dos objetivos de cada estudo.
Apresentação de dados descritivos em texto e em tabelas
Muitos estudos de tratamento de feridas originam demasiados dados para que seja possível apresentá-los apenas em texto. Muitas vezes apenas os resultados chave são apresentados em texto, com a maior parte dos dados a surgirem em forma de tabela, possivelmente num apêndice. Seja em texto ou em forma de tabela, a apresentação padrão de uma variável numérica é uma medida de média, seguida de uma medida de dispersão (ou seja, propagação) entre parênteses. A medida da média considerada é quase sempre a média (ou seja, a média aritmética) ou a mediana. As medianas, que não são distorcidas por valores periféricos, são geralmente preferidas quando os dados são suscetíveis de serem distorcidos – tais como o tempo para a cicatrização de feridas ou algum outro evento, ou quando estamos a lidar com quantidades ordinais (como a soma dos itens do questionário ao estilo Likert), que se assume serem equivalentes aos dados numéricos - caso contrário, a média, que utiliza todos os valores dos dados, é geralmente a preferida.
A medida de dispersão considerada é geralmente o desvio padrão (geralmente abreviado para SD) ou a gama e/ou intervalo interquartil (geralmente abreviado para IQR). O intervalo de um conjunto de dados é fácil de calcular (é simplesmente a diferença entre os dois valores extremos) mas baseia-se apenas nessas duas medidas, ignorando todas as outras. É distorcida por valores atípicos. O IQR, que é calculado como o intervalo do percentil 25 ao 75 dos dados, é mais robusto à distorção, mas também ainda não tem em conta grande parte do conjunto de dados.
Pelo contrário, o SD utiliza todas as observações, mas pode ser sensível a valores atípicos e é geralmente inadequado para dados enviesados. Tem também a vantagem de estar sempre nas mesmas unidades de medida que os dados em bruto, o que pode ajudar na sua interpretação; nos dados normalmente distribuídos, aproximadamente dois terços de todas as observações situar-se-ão dentro de um desvio padrão da média. Assim, por exemplo, se nos for dito que o diâmetro médio da ferida, num grande estudo de úlceras de perna venosa, é de 20 mm, com um SD de 4 mm, então se os dados forem normalmente distribuídos, podemos inferir que cerca de dois terços das feridas têm um diâmetro entre 16 mm (1 SD abaixo da média) e 24 mm (1 SD acima da média). O restante um terço das feridas seria de esperar que fossem relativamente atípicos, quer de diâmetro inferior a 16 mm ou de diâmetro superior a 24 mm.
Os emparelhamentos comuns para apresentação de dados descritivos são: média e SD, mediana e amplitude e mediana e IQR. Outras medidas de média e dispersão, tais como a média geométrica, modo e gama média, são encontradas com muito menor frequência.
A apresentação padrão para uma variável categórica é a frequência, complementada com a percentagem e/ou proporção. Geralmente as percentagens válidas são consideradas ignorando os dados inválidos ou em falta. Por exemplo, uma auditoria de lesões por pressão numa determinada UCI de uma enfermaria hospitalar pode registar uma série de lesões por pressão nas Etapas 1, 2 e 3 em pacientes da UCI, mas alguns pacientes da enfermaria podem não ser auditados. Seria provavelmente mais apropriado citar o número de pacientes com uma lesão por pressão de fase 1 como uma proporção (e/ou percentagem) dos pacientes que foram efetivamente auditados e não como uma proporção de todos os pacientes.
O quadro 1, adaptado de Ousey et al.1, mostra um exemplo de dados tabelados num formato bastante típico. Inclui tanto uma variável numérica (idade), resumida utilizando média e DS em cada grupo de estudo, como várias variáveis categóricas, resumidas utilizando a frequência e a percentagem válida. Aqui a proporção é também indicada. Os níveis de cada variável categórica que foi considerada estão indentados abaixo do nome da própria variável. Esta quantidade de dados seria difícil de absorver em texto e o formato lado a lado do quadro facilita uma comparação fácil das características do grupo, as quais não seriam tão aparentes em dados apresentados em forma de texto.
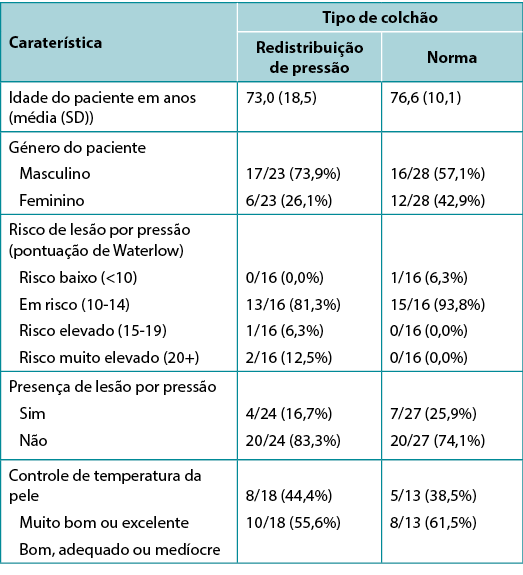
Quadro 1. Exemplo de dados em tabela [adaptado1]
Note-se que o denominador é diferente para as diferentes características dos pacientes que são apresentados na tabela; não terão sido relatadas todas as características em todos os pacientes. Os níveis da variável de controle de temperatura da pele foram 'condensados' a partir de cinco categorias individuais em dois níveis contrastantes; esta é uma estratégia comum quando os dados estão dispersos de forma demasiado fina por vários níveis, de forma a permitir uma análise significativa, ou quando se destaca um contraste entre dois estados clínicos significativos. A variável Waterlow foi transformada da sua escala numérica original numa variável categórica ordinal; assumindo o custo de uma certa perda de informação, isto também permite a comparação entre os níveis de risco na utilização clínica comum.
Apresentação em forma gráfica de dados descritivos
Estão disponíveis muitos tipos diferentes de gráficos e a maioria deles pode ser facilmente produzida utilizando software moderno. No entanto, nem todos os gráficos são apropriados para todos os tipos de dados. Os gráficos de pizza e os gráficos de barras são ambos concebidos para ilustrar visualmente as frequências relativas de múltiplos níveis de variáveis categóricas. Apesar da sua ubiquidade, o gráfico de pizza aparentemente não parece oferecer nada que uma barra não ofereça; a maioria das pessoas tem mais dificuldade em avaliar o tamanho relativo dos sectores de um círculo do que as alturas das colunas. Nenhuma das representações funciona bem para exibir um número muito grande de categorias (as quais são difíceis de comparar visualmente).
O gráfico de barras também pode ser utilizado para representar uma quantidade expressa em proporção - Ousey et al.2 apresentaram a proporção de pacientes com ulceração de pressão antes e depois da implementação de um programa de redução de pressão através de um gráfico de barras simples (Figura 1). A "sinalética" em torno das barras representam intervalos de confiança, uma medida da incerteza na quantidade a ser medida.
Figura 1. Exemplo de um gráfico de barras simples [adaptado2]
Uma extensão útil do gráfico de barras pode encontrar-se no gráfico de barras agrupado, o qual permite a exibição de dois fatores em simultâneo. A figura 2 é uma representação clara da interação entre dois fatores categóricos - estado do sistema de classificação por pressão (com níveis representados pelos clusters da esquerda e da direita) e a política de encaminhamento (barras dentro de cada cluster).
Figura 2. Exemplo de um gráfico de barras agrupadas [adaptado3]
Para os dados numéricos são necessárias diferentes representações. Como exemplo, um histograma, o qual é frequentemente confundido com um gráfico de barras, foi utilizado por Barakat-Johnson et al.4 para representar o tempo de resposta à comunicação com um especialista em feridas, informado pelos pacientes utilizando uma aplicação digital (Figura 3). Este pode ser distinguido de um gráfico de barras pela inexistência de espaços entre as barras, refletindo a representação de uma medida contínua em vez de categorias distintas. Este tipo de dados também pode ser representado utilizando um diagrama de caixa, embora os diagramas de caixa não forneçam informações sobre a distribuição completa de um conjunto de dados.
Figura 3. Exemplo de um histograma [adaptado4]
Representação mista
A relação entre uma variável numérica (como o índice de pressão de pico) e as variáveis categóricas (como a categoria do IMC e a posição do corpo) pode ser ordenadamente combinada numa única representação usando um gráfico de linhas, como relatado por Coyer et al.5. A figura 4 mostra a posição do corpo, distinguida pela cor e pelo sombreamento da linha e a categoria do IMC pela posição no eixo x.
A principal mensagem deste gráfico para levar para casa é que os fatores interagem - o efeito sobre o pico de pressão da categoria IMC depende de onde é medido. Se os mesmos dados tivessem sido apresentados em forma de tabela este efeito não seria imediatamente visível
Figura 4. Exemplo de um gráfico de linhas [adaptado5]
Medidas repetidas
Muitos estudos de tratamento de feridas são adequados para medições repetidas, por exemplo, para examinar a trajetória de cicatrização de uma ferida, monitorizando a sua duração a intervalos semanais até à sua cicatrização, ou a investigação de tendências através de auditorias de dados agregados institucionais. Stephenson et al.6 apresentaram dados longitudinais (neste caso, o número de observações de lesões por pressão de categoria 2, relatadas numa organização de saúde a intervalos mensais durante um período de vários anos) como um gráfico de linhas (Figura 5), com a linha pontilhada a ilustrar a tendência subjacente, dependente do tempo. Aqui o gráfico ilustra as tendências sazonais, uma tendência geral para a descida anual e a relação entre um ponto de dados e o ponto anterior (correlação automática) - efeitos que seriam quase impossíveis de discernir apenas a partir de dados em tabelas.
Figura 5. Exemplo de um gráfico de linhas mostrando dados longitudinais [adaptado6]
Tabelas ou gráficos?
Nem sempre é fácil decidir se é necessário utilizar um quadro, um gráfico ou ambos para resumir os dados. Os gráficos mostram tendências e padrões nos dados e a relação entre uma variável e outra, que não seria necessariamente aparente nos mesmos dados quando apresentados em forma de tabela. As tabelas dão valores a um nível de precisão que está geralmente indisponível na maioria das apresentações gráficas.
Conclusões
Uma apresentação eficaz dos dados descritivos dos cuidados com feridas pode permitir a um leitor absorver rapidamente tendências e padrões nos dados, comparar características de grupo, bem como avaliar a magnitude dos efeitos. As questões que surgem dos estudos de cuidados com feridas - nos quais podemos estar a tentar comparar os benefícios de um tratamento com outro, talvez examinar a alteração dos parâmetros das feridas ao longo do tempo, ou simplesmente resumir a extensão das feridas num estudo de auditoria - podem muitas das vezes ser respondidas de forma simples e eficaz utilizando uma análise descritiva, embora normalmente, tal análise seja seguida de uma avaliação inferencial. No entanto, a facilidade com que o software moderno permite elaborar gráficos de qualquer tipo pode, por vezes, constituir uma barreira à comunicação eficaz. Existem muitos exemplos publicados de gráficos que acrescentam pouco ou nada à compreensão, pelo que precisam de ser usados com cuidado.
Embora as estatísticas descritivas não facilitem o tirar conclusões para além dos dados disponíveis ou permitam rejeitar hipóteses de estudo, podem ser uma forma valiosa de acrescentar entendimento a um estudo e requerem pouco ou nenhum conhecimento estatístico especializado para poderem ser compreendidas.
Author(s)
John Stephenson
PHD FRSS(GradStat) CMath(MIMA)
Senior Lecturer in Biomedical Statistics
University of Huddersfield, United Kingdom
Email J.Stephenson@hud.ac.uk
References
- Ousey K, Stephenson J, Fleming L. Evaluating the Trezzo range of static foam surfaces: results of a comparative study. Wounds UK 2016;12(4):66–73. ISSN 1746-6814.
- Ousey K, Stephenson J, Blackburn J. Sub-epidermal moisture assessment as an adjunct to visual assessment in the reduction of pressure ulcer incidence. J Wound Care 2022;31(3).
- Ousey K, Kaye V, McCormick K, Stephenson J. Investigating staff knowledge of safeguarding and pressure ulcers in care homes. J Wound Care 2016;25(1).
- Barakat-Johnson et al. The viability and acceptability of a Virtual Wound Care Command Centre in Australia. Int Wound J 2022;1–17.
- Coyer F, Clark M, Slattery P, Thomas P, McNamara G, Edwards C, Ingleman J, Stephenson J, Ousey K. Exploring pressures, tissue reperfusion and body positioning: a pilot evaluation. J Wound Care 2017;26(10).
- Stephenson J, Ousey K, Blackburn J, Javid F. Using past performance to improve future clinical outcomes in pressure ulcer prevention. J Wound Care 2021;30(6).

